
In this PA, you will be writing a program that reads in a text file (perhaps containing the contents of a book, poem, article, etc) and produces an infographic based on the text. You will need to use one or more dictionaries to count words in the program. You may also use lists and / or sets. Below, you can see three example infographics that your program should be able to generate:
The infographic should contain the following information about the text:
You can take creative liberty with the colors, but the text and graphics displayed should be in roughly the same positions as what is show on this spec.
The canvas size should be proportional to mine (650 pixels wide, 700 pixels tall), but it does not have to be exactly this.
Name the file infographic.py.
You should also re-download graphics.py, and use that for the graphical component.
The first step should be to ask the user for the input file that they would like to have an infographic created for.
Once the file has been selected, you can read in all of the lines and strip the newlines off of the ends.
To get the words, all you have to do is split each line on whitespace.
To accomplish this, just call split() on each line string, with no argument.
You can then append each individual word to a python list.
You do not need to strip off punctuation from the words or normalize the cases.
For example, if you input file had the following content:
two forks.
one knife.
two glasses.
one plate.
one naptkin.
his glasses.
his knife.
The words list should have the following content after processing the file:
words = ['two', 'forks.', 'one', 'knife.', 'two', 'glasses.', \
'one', 'plate.', 'one', 'naptkin.', 'his,' 'glasses.', 'his', 'knife.']
Once you have a list of all of the words from the file, you can count the occurrences. You should use a dictionary for this. Continuing from the example of the last step, the dictionary should have the following contents:
word_counts = {'two':2, 'one':3, 'forks.':1, 'knife.':2, \
'glasses.':2, 'plate.':1, 'naptkin.':1, 'his':2}
Next, you can find the small, medium, and large words that occur the most.
In the example, it would be one for small, knife. for medium, and glasses. for large.
You can do this by iterating through the key and value pairs in the word_counts dictionary, and keeping track of which has the highest count.
Then, display these on the canvas.
Next, compute how many unique capitalized and non-capitalized.
You can do this by getting the keys of the word_counts dictionary as a list, and then looping through them all.
Compute how many unique punctuated and non-punctuated words there are. Use a similar process as you did for step (4).
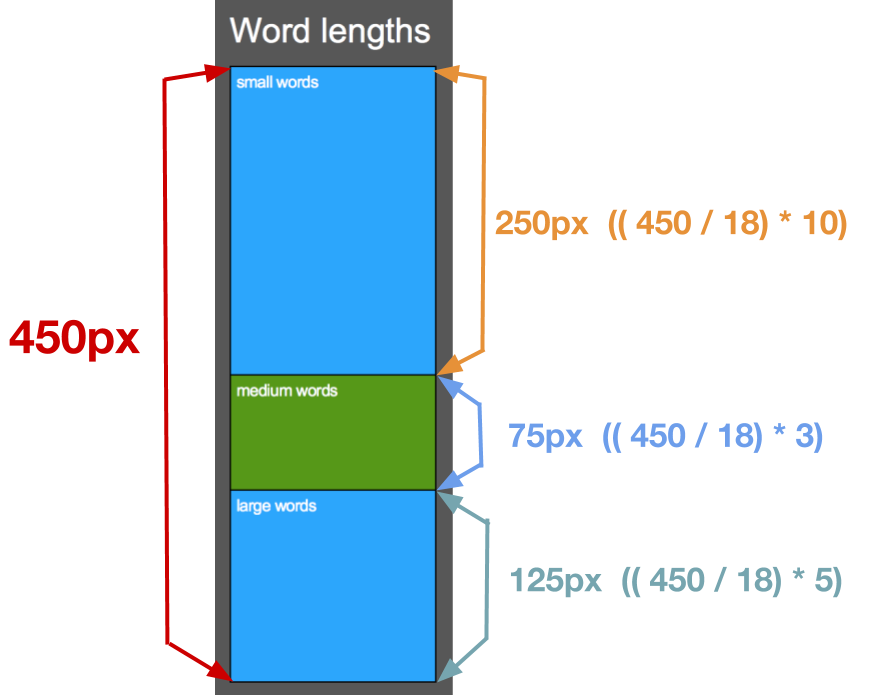
You should display two (or three, if doing the extra credit) bar charts on the infographic. This section will walk though how to build it the Small, Medium, and Large word Bar Chart (SMLBC). You can apply similar steps to the other two.
Let’s say you were trying to build the SMLBC for an input file with 10 unique short words, 3 unique medium words, and 5 unique large words. In total, this is 18 unique words. The small box should consume 10/18 of the whole bar, the medium bar should consume 3/18 of the whole bar, the large word bar should consume 5/18 of the whole bar. To calculate the height in pixels of each bar, use the formula:
(pixel_height / total_item_count) * category_item_count
For example, if the total height of the bar chart should be 450 pixels, then to get the height in pixels of the small word bar: (450 / 18) * 10.
Take a look at the image below for reference
Use this information to draw the other one or two bar charts.
Below are some resource files you might find interesting to run your program with.
If you’d like to try the program on other books, you can visit www.gutenberg.org.
Most of the test cases on Gradescope will not be super large. They will be 1000 lines of text at most.
Below are several examples, with the input files included. If you are not completing the extra credit, you only need to include the first two bar charts.
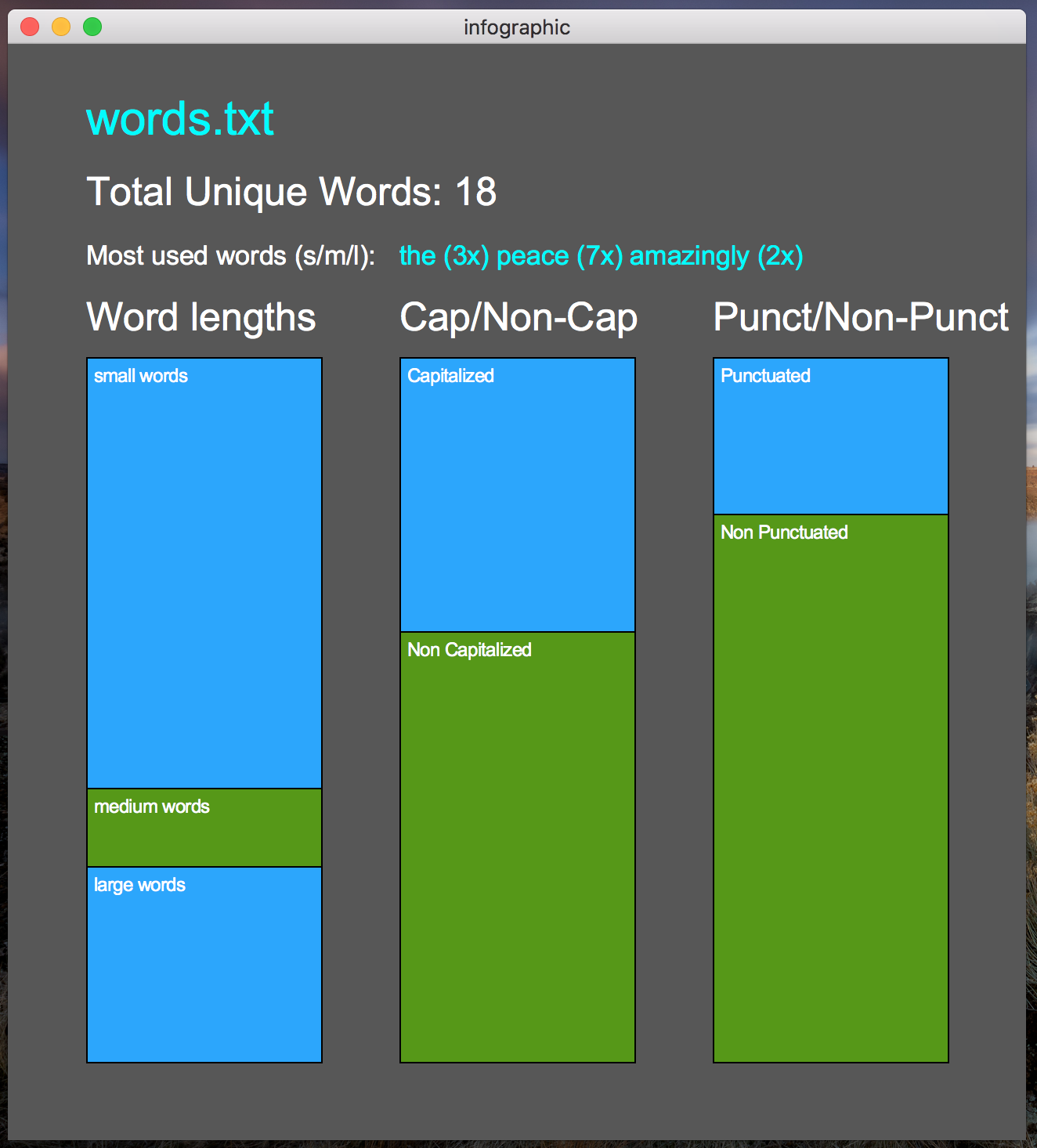 |
words.txt |
 |
Cat_in_the_Hat.txt |
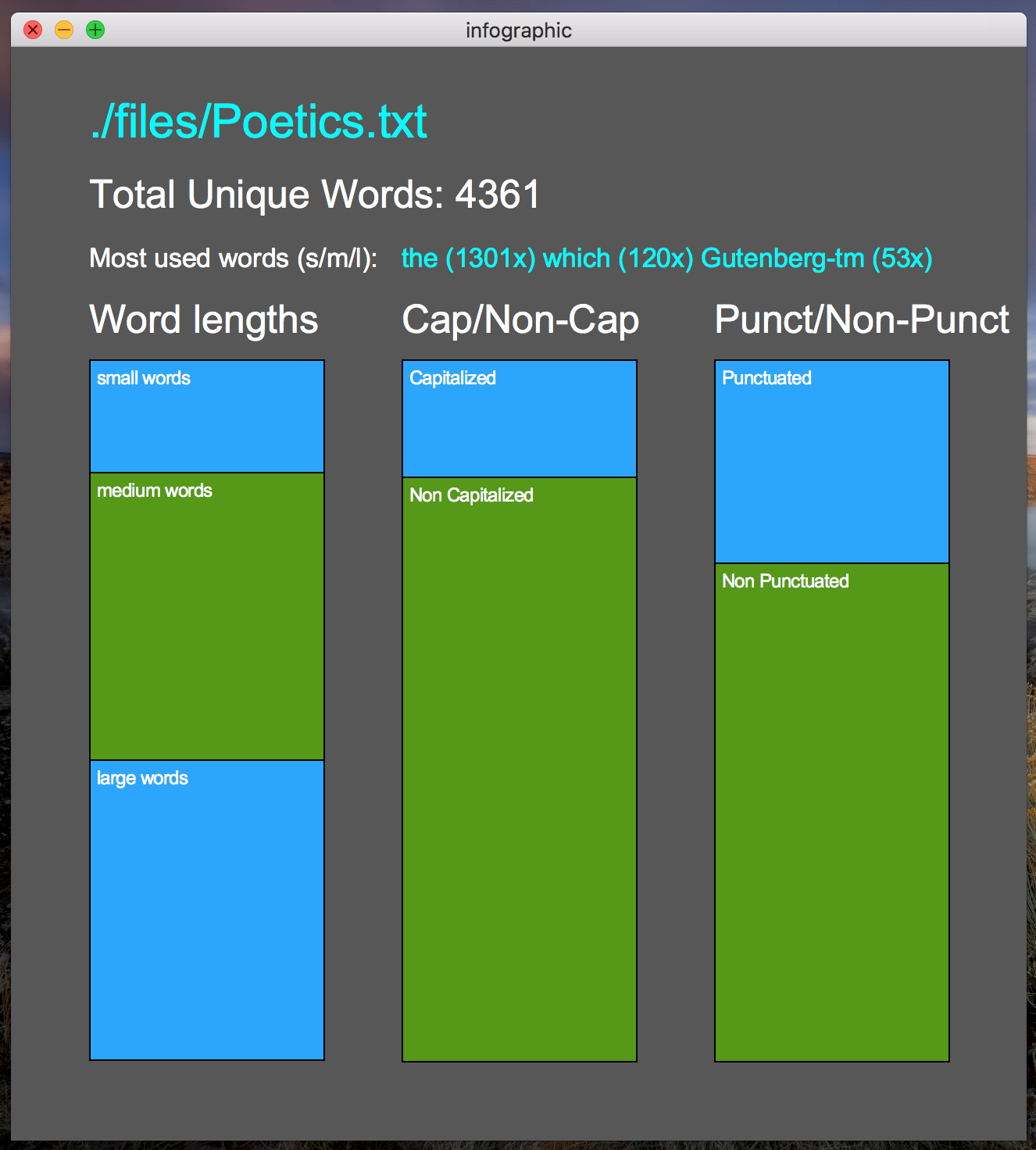 |
Poetics.txt |
 |
values.txt |
Submit this program to Gradescope by Tuesday, 4/21 by 7:00pm.
Special thanks to Ping Hsu, whose programming assignment spec this was partially inspired by!